文章目录
- 1. 定义
- 2. 数据倾斜
- 2.1 Map
- 2.2 Join
- 2.3 Reduce
- 3. 写在最后
1. 定义
数据倾斜,也称为Data Skew,是在分布式计算环境中,由于数据分布不均匀导致某些任务处理的数据量远大于其他任务,从而形成性能瓶颈的现象。这种情况在Hive中尤为常见,可能发生在MapReduce作业的Map或Reduce阶段。
就好比像是在一个拥挤的超市里,所有的顾客都挤在一个收银台前排队结账,而其他的收银台却几乎没有人。这种情况在数据处理中也会发生,我们称之为“数据倾斜”。
想象一下,你有一个巨大的数据集,需要分成很多小块来同时处理(这就像超市开了很多个收银台)。理想情况下,每个收银台(或者说数据处理任务)应该处理差不多数量的数据块。但有时候,由于数据的某些特征或者我们的处理方式,大部分数据块都被送到了同一个任务那里,导致这个任务要处理的数据远远多于其他任务。
数据倾斜的常见表现包括:
- 任务进度长时间维持在
99%,少数Reduce任务未完成。 - 单一
Reduce的记录数与平均记录数差异极大。
2. 数据倾斜
MapReduce执行过程可以简化为以下几个主要步骤:
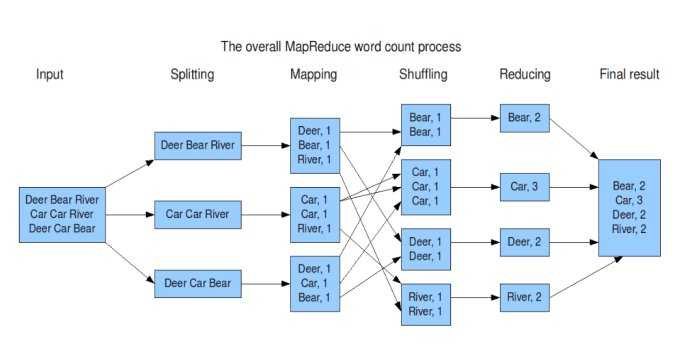
输入阶段(Input):
- 数据从HDFS等存储系统中读取到MapReduce作业。
映射阶段(Map):
- 输入数据被分割成多个chunks,每个chunk由一个Map任务处理。
- Map任务对数据进行处理,输出中间key-value对。
洗牌阶段(Shuffle):
- 中间key-value对根据key进行排序和分组。
- 相同key的数据被发送到同一个Reducer。
排序阶段(Sort):
- 数据在Shuffle过程中被排序,确保相同key的数据聚集在一起。
归约阶段(Reduce):
- Reducer接收分组后的数据,对每个key对应的value进行归约处理,如求和、合并等。
输出阶段(Output):
- 最终结果被写回到存储系统中,通常是HDFS。
Hadoop基础-07-MapReduce概述
2.1 Map
- 映射阶段(Map):
- 输入数据被分割成多个chunks,每个chunk由一个Map任务处理。
- Map任务对数据进行处理,输出中间key-value对。
Map阶段倾斜,或者说Map端数据倾斜,会遇到一些Map实例承担了不成比例的重担,而另一些Map实例却相对轻松。这种现象,我们称之为Map端的长尾效应,通常发生在以下情况:
-
小文件过多:当
Hive处理的输入数据包含大量小文件时,每个小文件都可能被当作一个独立的任务处理。如果这些小文件数量极多,会导致生成大量的Map任务,每个任务处理的数据量很少,但任务的启动和初始化开销却相对较大,这会造成资源的浪费和处理效率的降低。 -
数据块大小不均:如果输入数据的块大小差异很大,比如一个大文件和许多小文件,这可能导致
Map任务处理的数据量不均衡。大文件可能被分割成多个任务,而小文件则可能保持独立,导致某些Map任务处理的数据远多于其他任务。 -
Map任务逻辑复杂:即使数据块大小相对均匀,如果
Map端的计算逻辑非常复杂,比如Count Distinct时,如果某些Map实例读取到的特定值频繁出现,这将导致这些实例处理的数据量激增,形成长尾。这一种涉及到大量的条件判断或聚合操作,也可能导致某些Map任务执行时间过长。 -
数据源倾斜:输入数据在物理或逻辑上分布不均,造成某些
Map任务分配到的数据远多于其他任务。
Map端倾斜的具体表现可能包括:
- 部分
Map任务进度缓慢,而其他任务已经完成。 - 资源使用不均衡,某些节点或任务长时间占用大量资源。
- 作业整体执行时间长,因为等待最慢的Map任务完成。
总而言之一句话:输入文件的大小不均匀。
解决Map端倾斜的方法可能包括:
- 合并小文件:在作业执行前,通过
set hive.merge.mapfiles=true合并小文件,减少Map任务的数量。 - 调整Map任务数量:通过设置
mapred.map.tasks参数来增加或减少Map任务的数量,以适应数据量和计算复杂性。 - 优化输入格式:选择合适的输入格式,比如使用Hive的
InputFormat来优化数据的读取。 - 简化Map逻辑:优化Map端的代码逻辑,减少不必要的计算和数据移动。
2.2 Join
- 排序阶段(Sort):
- 数据在Shuffle过程中被排序,确保相同key的数据聚集在一起。
Reduce阶段倾斜可能是由于Map阶段输出的键值对分布不均匀,或者Reduce任务逻辑处理复杂度高导致的。
Join阶段常见的数据倾斜场景及其解决方法:
-
MapJoin优化小输入场景:
- 当我们进行Join操作时,如果其中一个表的数据量很小,可以把它整个加载到内存中。
-
处理空值导致的长尾:
- 如果Join操作中,由于某些空值字段导致大量数据集中在少数几个处理节点上,我们可以把这些空值替换为随机分配的值。
-
热点值导致的长尾处理:
- 当Join操作涉及两个大表,而且某个或某些特定的值(热点值)非常常见,导致数据处理时出现瓶颈,我们可以把这些热点值和非热点值分开处理。
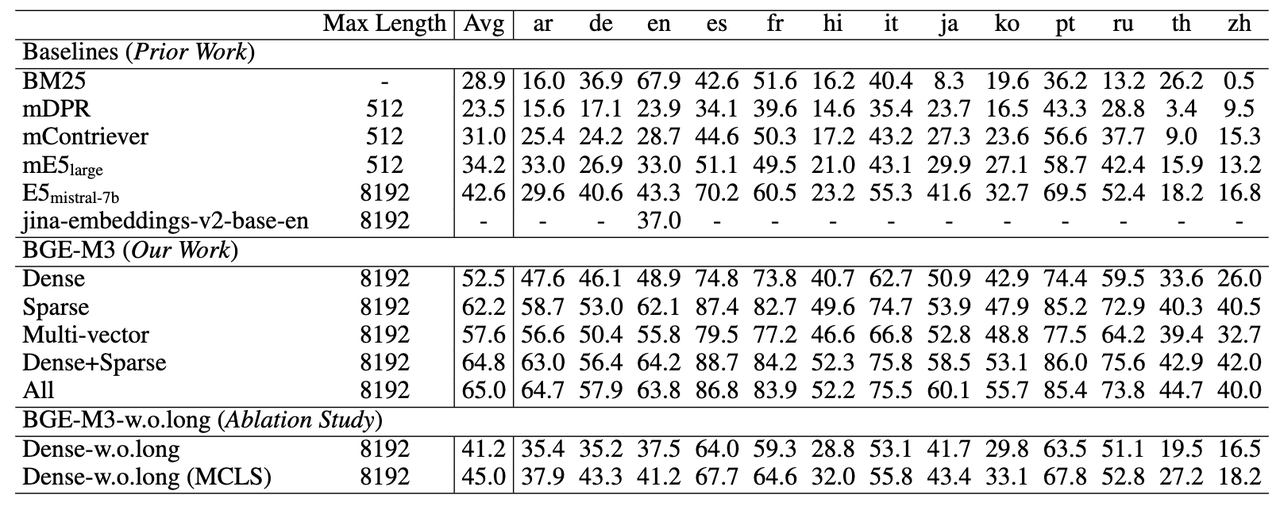
以下是将Join倾斜的解决方案与出现场景整理成表格的形式:
| 倾斜场景 | 问题描述 | 解决方案 | 具体方法 |
|---|---|---|---|
| MapJoin适用 | Join操作中某路输入较小 | 使用MapJoin避免倾斜 | 将小表读入内存,在Map端完成Join操作,避免数据在Reduce端的不均匀分发。 |
| 空值导致长尾 | 关联key出现大量空值 | 将空值处理成随机值 | 空值无法参与Join,转换为空值的随机分配,既不影响结果,也避免数据聚集。 |
| 热点值导致长尾 | Join输入较大且存在热点值 | 热点值和非热点值分别处理 | 识别热点key,将数据分为热点和非热点两部分,分别进行Join操作后合并结果。 |
- MapJoin优化小输入场景:
SET hive.auto.convert.join = true;
SELECT /*+ MAPJOIN(small_table) */
a.id,
a.value,
b.description
FROM
large_table a
JOIN
small_table b
ON
a.key = b.key;
- 处理空值导致的长尾:
SELECT
COALESCE(a.key, CONCAT('random_', CAST(RAND() * 1000 AS INT))) AS key,
a.value,
b.description
FROM
large_table a
LEFT JOIN
another_table b
ON
COALESCE(a.key, CONCAT('random_', CAST(RAND() * 1000 AS INT))) = b.key;
- 热点值导致的长尾处理:
-- 处理非热点值
SELECT
a.id,
a.value,
b.description
FROM
large_table a
JOIN
another_large_table b
ON
a.key = b.key
WHERE
a.key NOT IN ('hot_value1', 'hot_value2');
-- 处理热点值
SELECT
a.id,
a.value,
b.description
FROM
large_table a
JOIN
another_large_table b
ON
a.key = b.key
WHERE
a.key IN ('hot_value1', 'hot_value2');
2.3 Reduce
- 归约阶段(Reduce):
- Reducer接收分组后的数据,对每个key对应的value进行归约处理,如求和、合并等。
Reducer导致的倾斜情况有很多,一句话归纳就是:键值分布不均匀导致分区不均衡,从而引起数据倾斜。
-
Map端数据膨胀:
- 场景:对同一表按不同维度进行Count Distinct操作,导致Map端数据膨胀,进而导致下游Join的Reduce阶段出现长尾。
- 解决方法:提前在Map端进行部分聚合,减少传输的数据量。
-
键值分布不均:
- 场景:Map端直接做聚合时,键值分布不均,导致单个Reducer负载过重。
- 解决方法:对键值添加随机前缀(盐值),均衡数据分布。
-
动态分区过多:
- 场景:动态分区数过多,造成小文件过多,引起Reduce端长尾。
- 解决方法:控制动态分区数量,合并小文件。
-
多个Distinct操作:
- 场景:SQL中多个Distinct操作导致数据多次分发,数据膨胀,放大长尾现象。
- 解决方法:合并多个Distinct操作,或优化查询逻辑以减少数据分发次数。
3. 写在最后
在数据处理倾斜的时候,我们需要采取多种策略来优化性能。从Map端到Reduce端,每个阶段的数据分布不均可能导致处理效率的严重下降,甚至造成作业执行时间的显著延长。
通过本文探讨的Map端数据膨胀、Reduce端键值分布不均、以及动态分区过多等典型场景,我们深入分析了每种情况的解决方案。在实际应用中,我们应该根据具体情况灵活调整,采取合适的优化策略,以提升Hive作业的整体性能和稳定性。